Assignment #1 -- Perceptron
題目
我的答案
如何執行 ( Execution Description )
把 perceptron_code.ipynb 檔案以 GOOGLE COLAB 開啟。
點選 執行階段 > 全部執行 。
實驗結果 ( Experimental Results )
題目 1 實驗結果:
我實作 rand_sample_generation 這個 function ,其有兩個參數 pos_n 和 neg_n ,分別代表 positive label 的資料數量以及 negative label 的資料數量。
rand_sample_generation 有定義題目所要求的一直線,如下:
rand_sample_generation 會在 0.7 * x_tmp - y_tmp + 0.3 != 0 的時候才產生樣本,也就是說不會產生落在線上的樣本。
rand_sample_generation 會產生出指定數量的樣本並且以 random.shuffle 打亂順序。
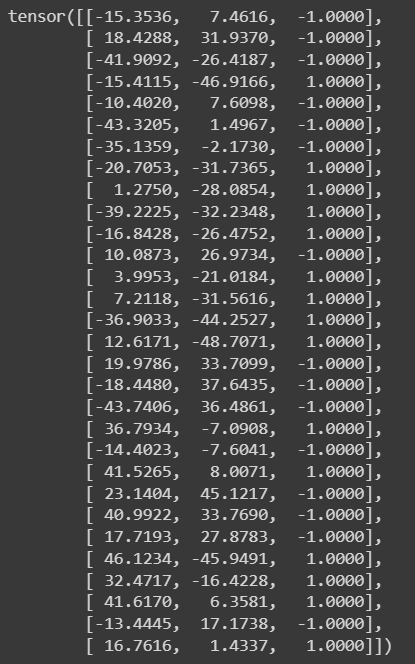
使用以下程式碼便可以產生樣本 ( 樣本附帶 label ) ,付上結果截圖:
1 2 3 data = rand_sample_generation(15 , 15 ) print (data)
題目 2 實驗結果:
題目 3 實驗結果:
題目 4 實驗結果:
結果觀察 ( Conclusion )
題目 1 結果觀察:
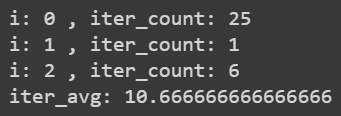
題目 2 結果觀察:
PLA 會停止。
平均下來會經過大約 10.67 次之後停止。
題目 3 結果觀察:
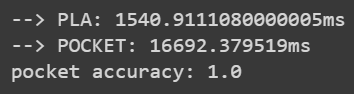
發現 pocket_alg 的 max iteration 上限值夠大時,其會花比較多時間執行。
題目 4 結果觀察:
如果把數據混入 mislabeled data ,那 pocket_alg 得出來的準確率會降低。
相關討論 ( Disscussion )
PLA 何時需要更新?
相同 label 但是不同邊或者是不同 label 同一邊時要更新,可以理解成用相乘為負值時需要更新。
實作 need_update function :
1 2 3 4 5 6 def need_update (v1, v2, label ): res = label * torch.dot(v1, v2) if res < 0 : return True else : return False
pocket_alg 有時候會比 PLA 快?
如果 pocket_alg 的 max iteration 值設得不夠大時有可能會發生,而且 iteration 太低可能會影響準確率,故我多次嘗試把 iteration 調整到 200 次,目前這個調整可以顯示出預期的結果。
程式碼 ( Code )
也可以參考 perceptron_code.ipynb 檔案。
1 2 3 4 import torchfrom torch import nnprint (torch.__version__)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 import randomtorch.manual_seed(42 ) def rand_sample_generation (pos_n, neg_n ): m = 0.7 b = 0.3 pos = [] neg = [] while True : x_tmp = random.random() * 100 - 50 y_tmp = random.random() * 100 - 50 if m * x_tmp - y_tmp + b > 0 and len (pos) < pos_n: pos.append([x_tmp, y_tmp, 1 ]) elif m * x_tmp - y_tmp + b < 0 and len (neg) < neg_n: neg.append([x_tmp, y_tmp, -1 ]) if len (pos) == pos_n and len (neg) == neg_n: break sample = pos + neg random.shuffle(sample) sample_tensor = torch.tensor(sample, dtype=torch.float32) return sample_tensor
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 def need_update (v1, v2, label ): res = label * torch.dot(v1, v2) if res < 0 : return True else : return False def PLA (data, weight, max_iter=1000 , lr=1 ): iter_count = 0 for i in range (max_iter): update_count = 0 for j in range (len (data)): data_vec = torch.cat(( data[j][:2 ], torch.tensor([1 ], dtype=torch.float32) )) label = data[j][2 :3 ] if need_update(data_vec, weight, label): weight = weight + lr * label * data_vec update_count = update_count + 1 if update_count == 0 : break iter_count = iter_count + 1 return weight, iter_count
1 2 3 weight = torch.rand(3 ) print (weight)
1 2 3 data = rand_sample_generation(15 , 15 ) print (data)
1 2 3 fin_weight, iter_count = PLA(data, weight) print ("fin_weight:" , fin_weight)print ("iter_count:" , iter_count)
1 2 3 4 5 6 7 8 9 iter_avg = 0 for i in range (3 ): data = rand_sample_generation(15 , 15 ) fin_weight, iter_count = PLA(data, weight) print ("i:" , i, ", iter_count:" , iter_count) iter_avg = iter_avg + iter_count iter_avg = iter_avg / 3 print ("iter_avg:" , iter_avg)
1 2 3 data = rand_sample_generation(1000 , 1000 ) print (data)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 def pocket_alg (data, max_iter=1000 , lr=1 ): weight = torch.rand(3 ) fin_weight = weight err_count_min = len (data) + 1 for i in range (max_iter): err_count = 0 for j in range (len (data)): data_vec = torch.cat(( data[j][:2 ], torch.tensor([1 ], dtype=torch.float32) )) label = data[j][2 :3 ] if need_update(data_vec, weight, label): weight = weight + lr * label * data_vec err_count = err_count + 1 if err_count_min > err_count: err_count_min = err_count fin_weight = weight err_rate = err_count / len (data) return fin_weight, err_rate
1 2 3 4 5 import timeweight = torch.rand(3 ) print (weight)
1 2 3 4 5 6 7 8 9 10 11 12 tic = time.process_time() fin_weight, iter_count = PLA(data, weight) toc = time.process_time() print ("--> PLA: " + str (1000 *(toc - tic)) + "ms" )tic = time.process_time() fin_weight, err_rate = pocket_alg(data, max_iter=200 ) toc = time.process_time() print ("--> POCKET: " + str (1000 *(toc - tic)) + "ms" )print ("pocket accuracy:" , 1 -err_rate)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 def rand_sample_generation_mis50 (pos_n, neg_n ): m = 0.7 b = 0.3 pos = [] neg = [] while True : x_tmp = random.random() * 100 - 50 y_tmp = random.random() * 100 - 50 if m * x_tmp - y_tmp + b > 0 and len (pos) < pos_n - 50 : pos.append([x_tmp, y_tmp, 1 ]) elif m * x_tmp - y_tmp + b < 0 and len (neg) < neg_n - 50 : neg.append([x_tmp, y_tmp, -1 ]) if len (pos) == pos_n - 50 and len (neg) == neg_n - 50 : break while True : x_tmp = random.random() * 100 - 50 y_tmp = random.random() * 100 - 50 if m * x_tmp - y_tmp + b > 0 and len (pos) < pos_n: pos.append([x_tmp, y_tmp, -1 ]) elif m * x_tmp - y_tmp + b < 0 and len (neg) < neg_n: neg.append([x_tmp, y_tmp, 1 ]) if len (pos) == pos_n and len (neg) == neg_n: break sample = pos + neg random.shuffle(sample) sample_tensor = torch.tensor(sample, dtype=torch.float32) return sample_tensor
1 2 data = rand_sample_generation(1000 , 1000 ) mis_data = rand_sample_generation_mis50(1000 , 1000 )
1 2 3 4 5 6 7 8 9 fin_weight, err_rate = pocket_alg(data, max_iter=200 ) print ("fin_weight:" , fin_weight, ", err_rate:" , err_rate)print ("pocket accuracy:" , 1 -err_rate)fin_weight_mis, err_rate_mis = pocket_alg(mis_data, max_iter=200 ) print ("fin_weight_mis:" , fin_weight_mis, ", err_rate_mis:" , err_rate_mis)print ("pocket accuracy (mis) :" , 1 -err_rate_mis)