
Data Mining Project 110_2
Data Mining Project 110_2
The slide in this post is written mainly in English. But I use Chinese to present the slide in this post. So I will use Chinese to explain through this post.
這篇文章中的簡報主要是用英文寫的,但是我在報告這個簡報時用的是中文,故這篇文章我會用中文來解釋此份簡報。
這份簡報撰寫於 110_2 學期,是「資料探勘與應用」課程的 Final Project。
簡報內容與說明
這次 project 的題目是關於「假新聞偵測」的實驗:

這邊是這次 project 的組員,考慮到可能有個資問題,我蓋掉了個資部分。總共有兩位組員,主題是我們一起想到的,我主要負責實驗設計、程式碼撰寫、簡報製作,另外一位組員主要負責資料尋找、提供實驗建議、程式碼建議,我們也有一起討論預測模型的選取:

這邊是目錄,內容依序為實驗動機、實驗目的、問題描述、實驗方法、實驗結果、結論、實際演示與參考資料:

實驗動機:

這邊是實驗目的,目標是檢測一則新聞是否「可信」,並且要有高準確率。這邊我有注意到,一個實驗結果具有高準確率不一定代表使用的預測模型是最好的,因為如果一個事件發生率是 99%,但是 1% 不發生是我們關注的部分,那如果模型預測永遠都是 100% 會發生,便會有 99% 準確率,但對於偵測那 1% 並無助益,故我們之後會參考各項數據來判定結果是不是符合我們預期:

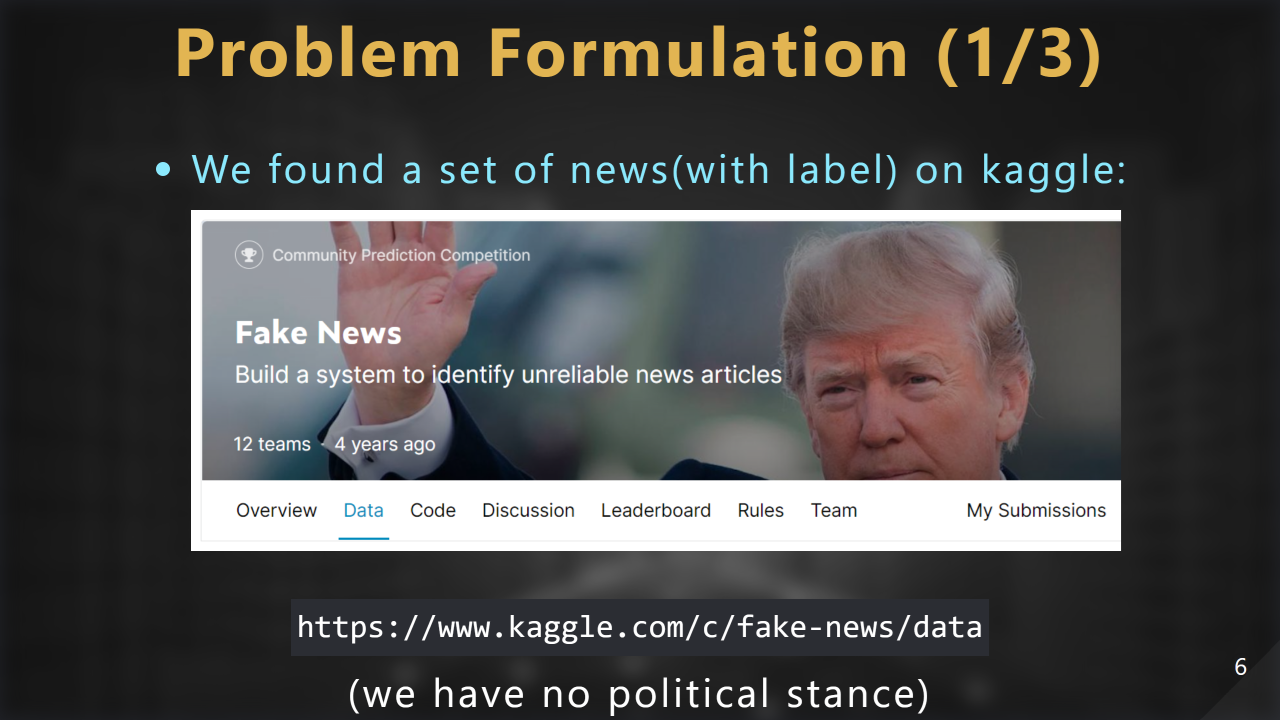
問題描述。在 Kaggle 上找到新聞相關資料,這份資料擁有 Title, Text, Author, LABEL(用於分辨是否可信) 這幾樣重要的 attribute,資料集裡⾯ label=1 代表 unreliable,label=0 代表 reliable,⽽我們的⼯作就是要根據 title、text 和 author 的資訊來判斷新聞的真偽:


接下來說明我們如何實踐我們的⽬標,主要分為前處理階段與訓練階段,我們使⽤的⼯具有 python 程式語⾔和 orange 軟體:

現在進入我們的前處理階段:

我們選取了資料集裡⾯ 4532 筆資料來當作我們的所有資料:
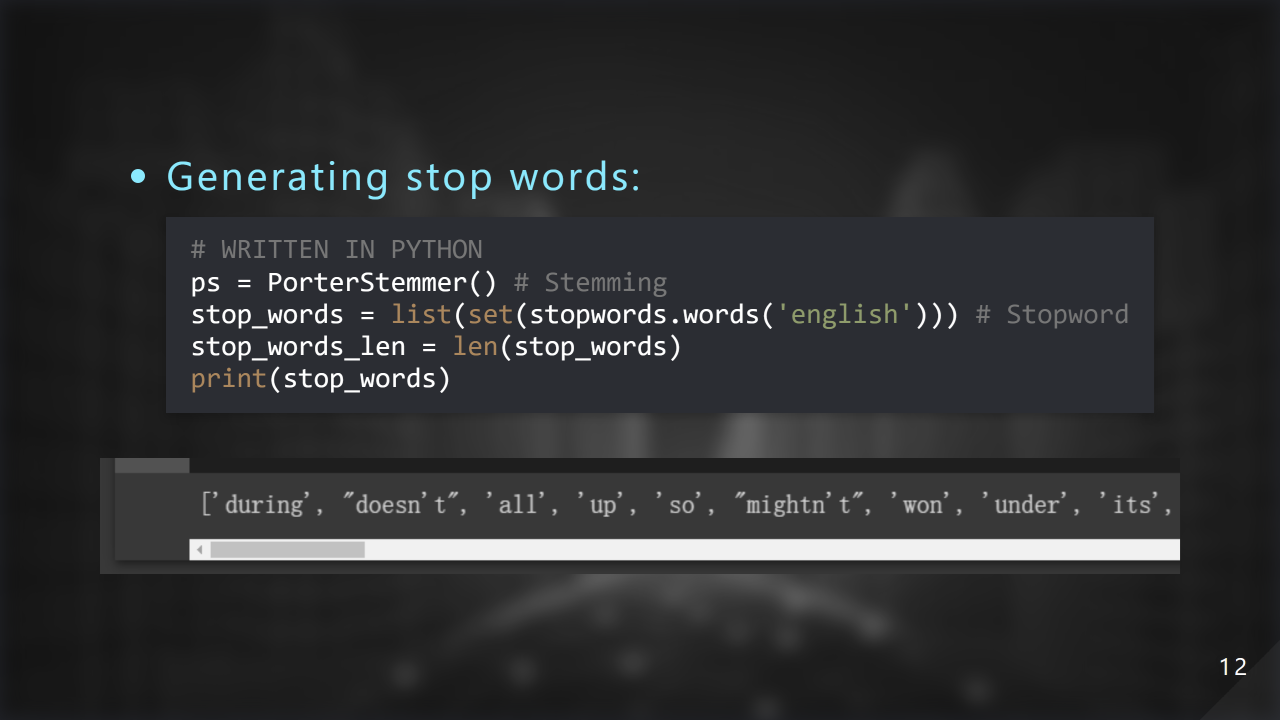
這邊是產⽣ stop words 的表格:
接著我們移除 stop word:
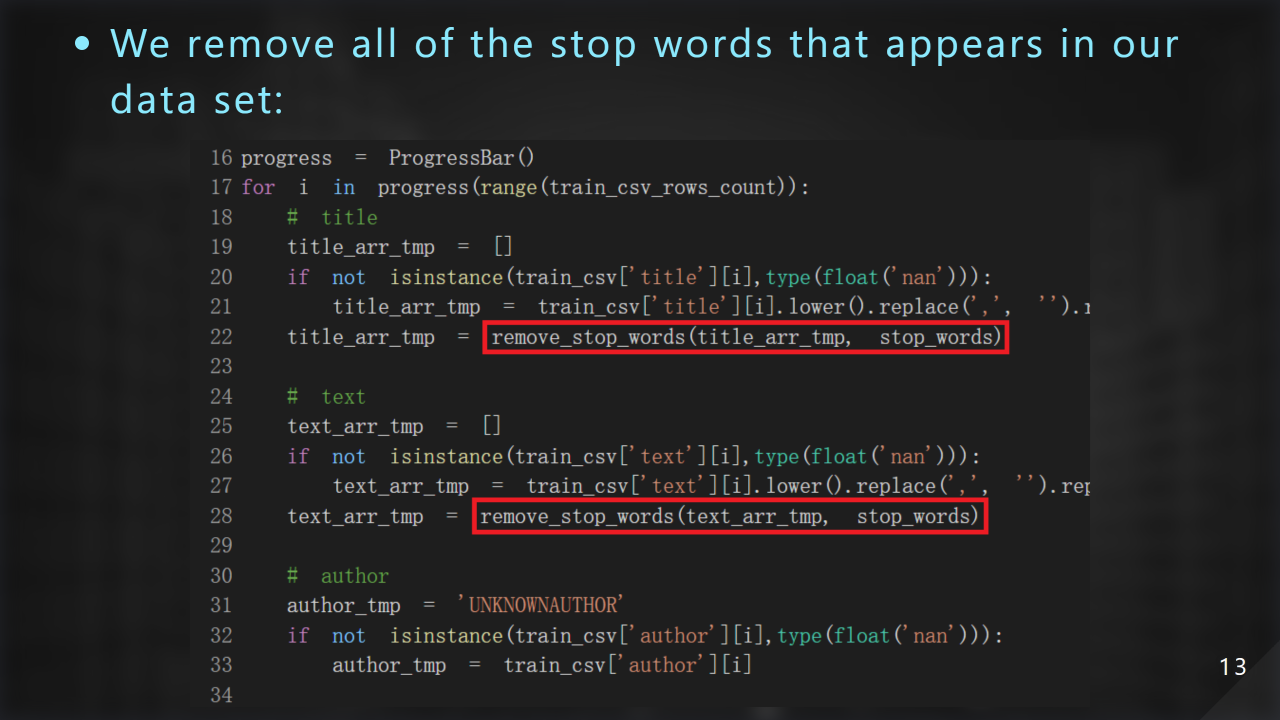
這邊注意到 author 並不⽤移除 stop word,只要移除 title 以及 text 的就好,因為之後我們可能會把 author 看作是⼀個類別資料,較為合理:

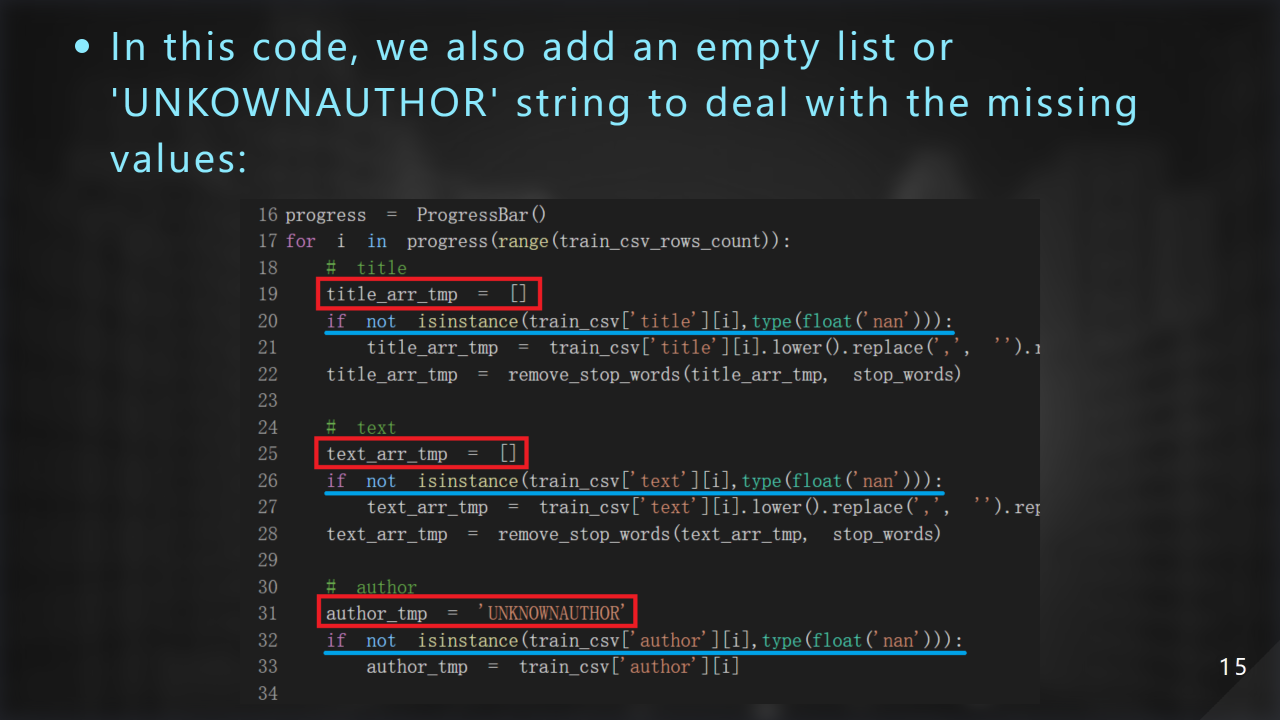
這邊我們做的動作是處理錯誤或遺漏直,因為⼀段文字我們視為⼀個 word list,所以 title、text 有缺的部份我們⽤ empty list 表⽰,author 有問題則以 unknown author 表⽰:
我們緊接著把 word list 丟進 Word2Vec 進⽽產⽣詞向量:
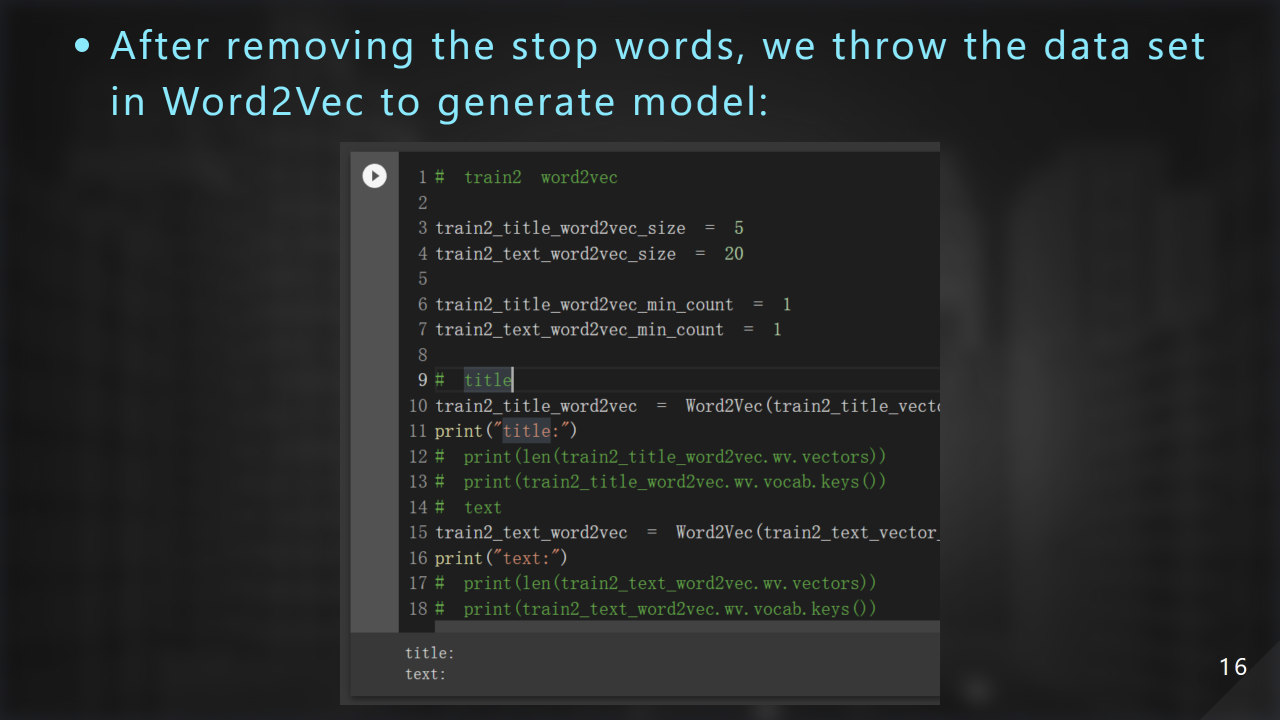
這邊是我們操作 Word2Vec 的細節,title 我們使⽤ 5 維向量,text 我們使⽤ 20 維向量。⾄於為什麼這樣設計?⾸先是 text 本⾝就比 title 常很多,應該擁有更⾼維度的表⽰⽅式;再來就是經過實驗 5 和 20 可以帶給我們滿意的結果,也就是⾼準確率:

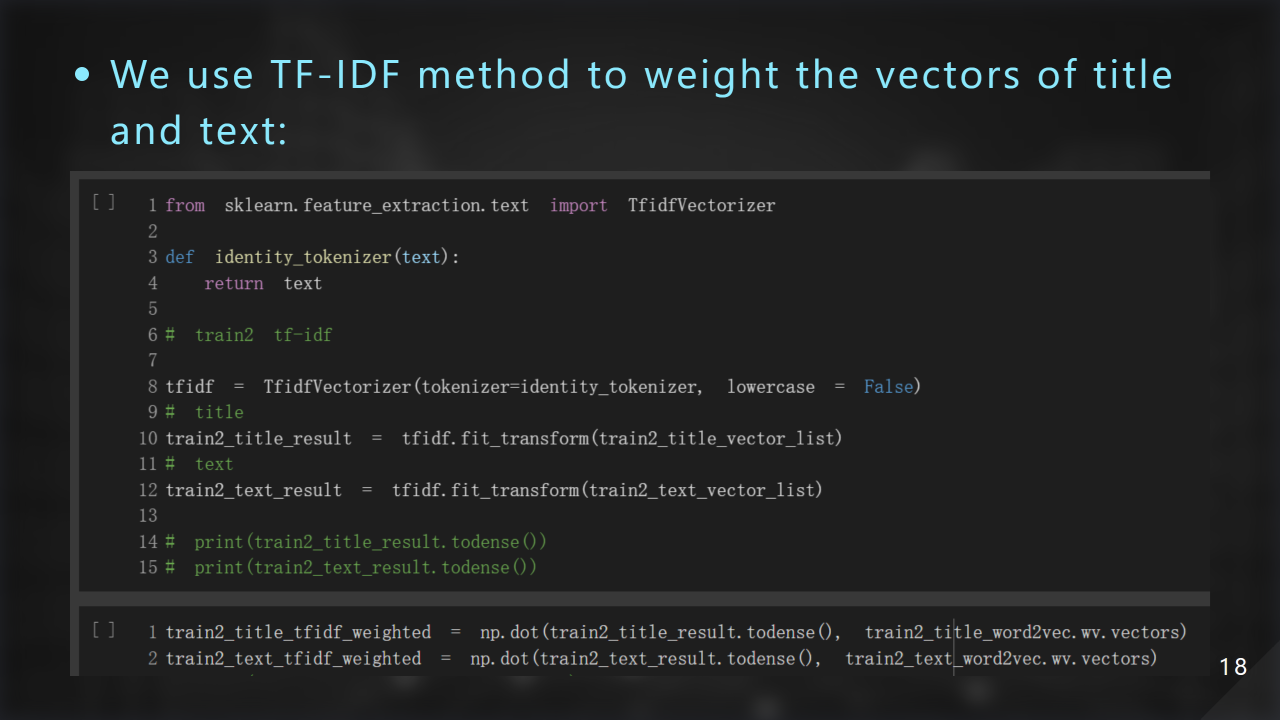
接著我們利⽤ TF-IDF 的⽅式把詞向量再做加權:
現在進入我們的訓練階段:

⾸先整理⼀下我們的資料經過前處理之後⻑甚麼樣⼦。前⾯是經過處理的兩組向量,接下來是 author、label:

這邊是把我們的檔案匯入 orange:
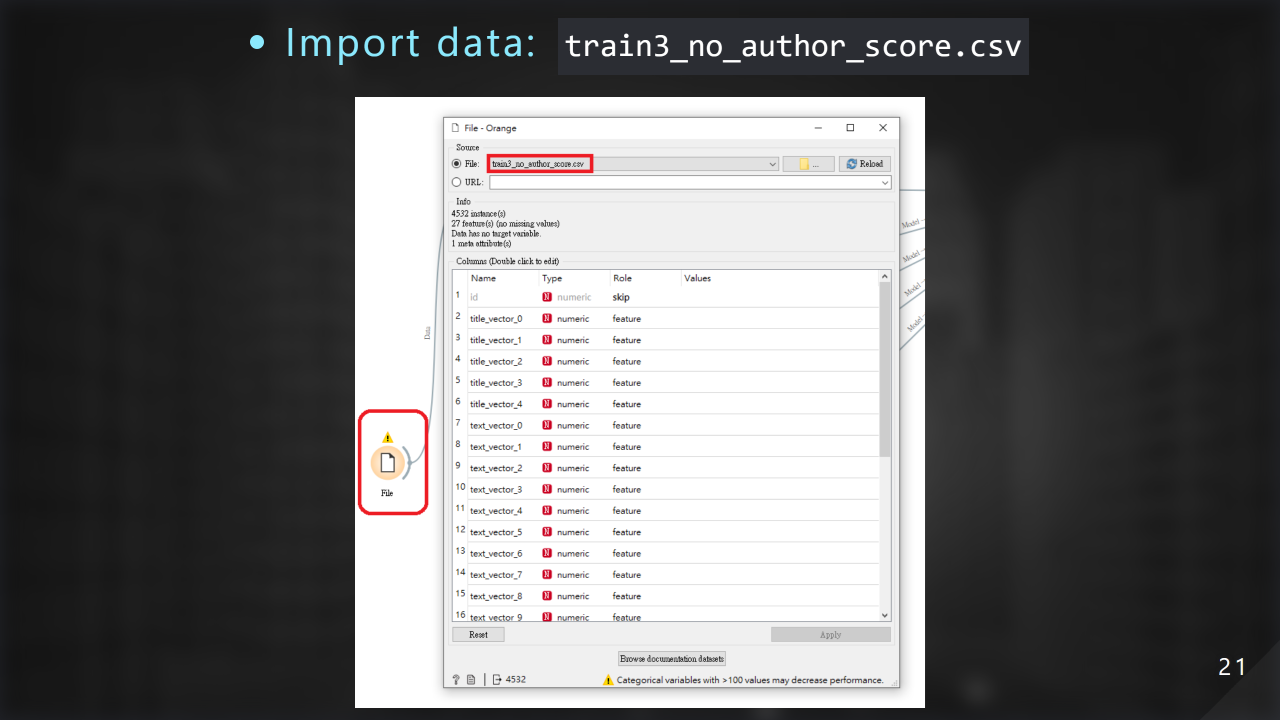
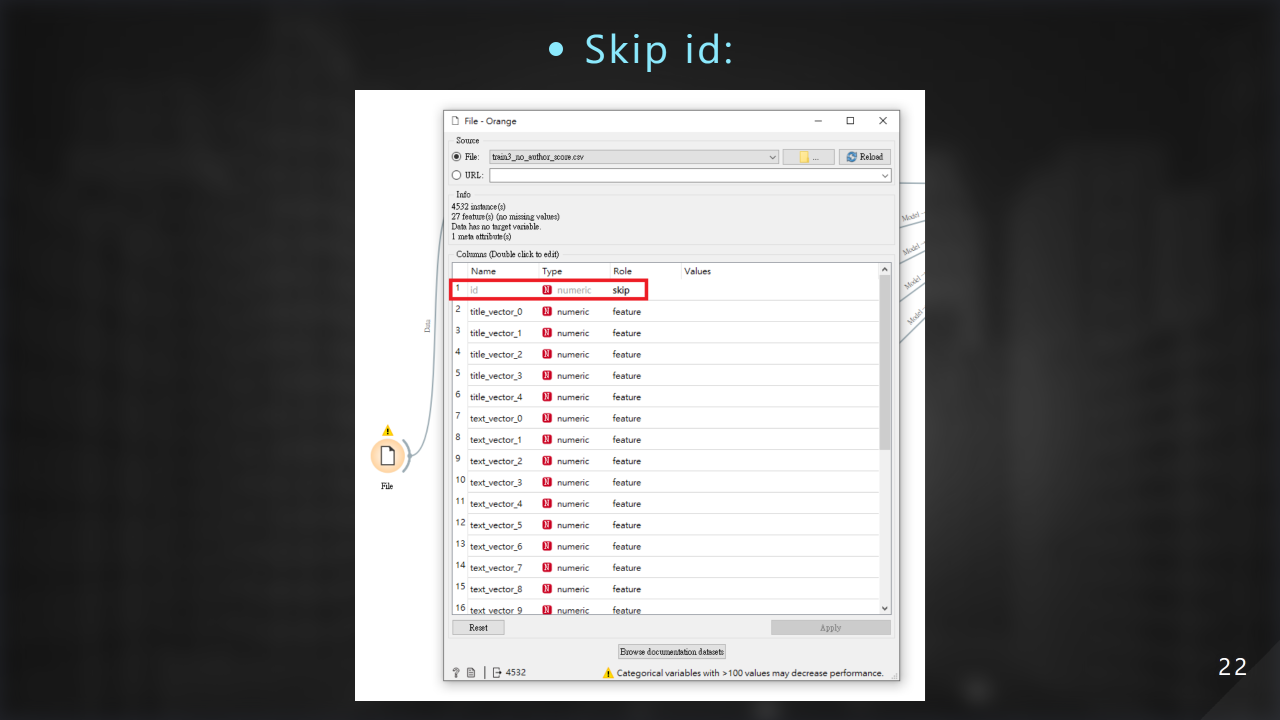
我們忽略掉 id 欄位:
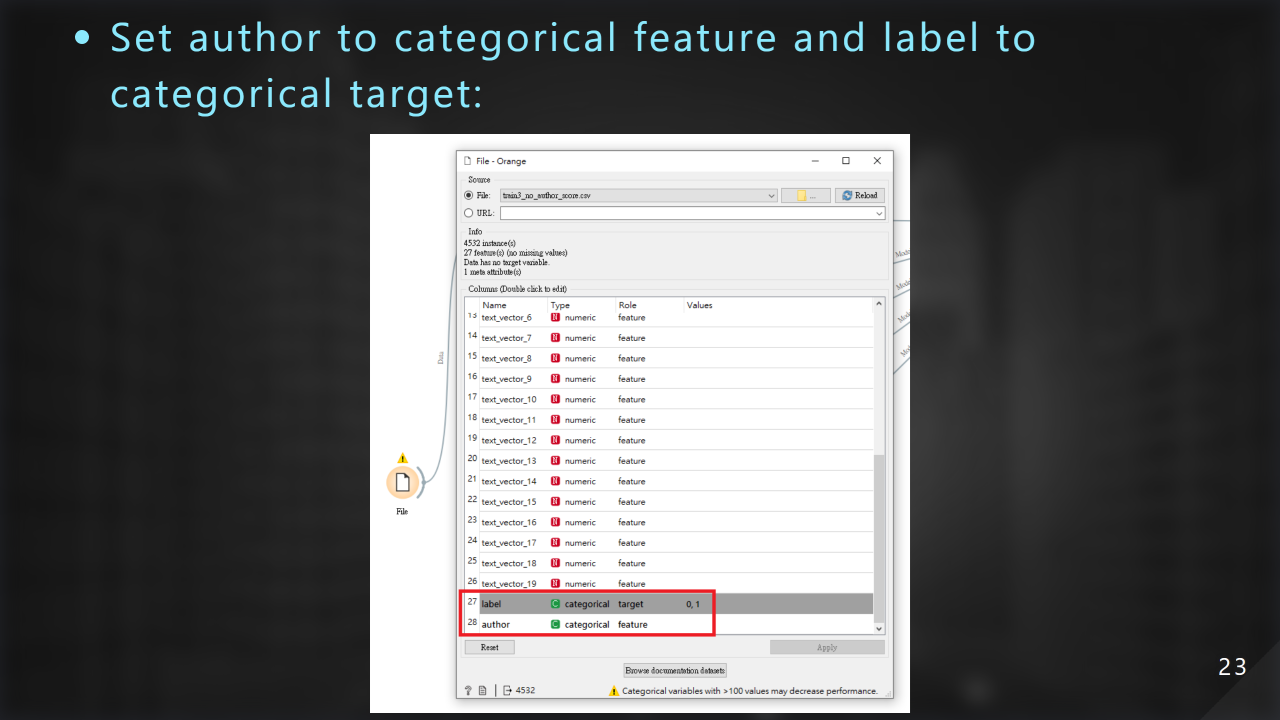
接著設定 author 為 categorical feature、label 為 categorical target:
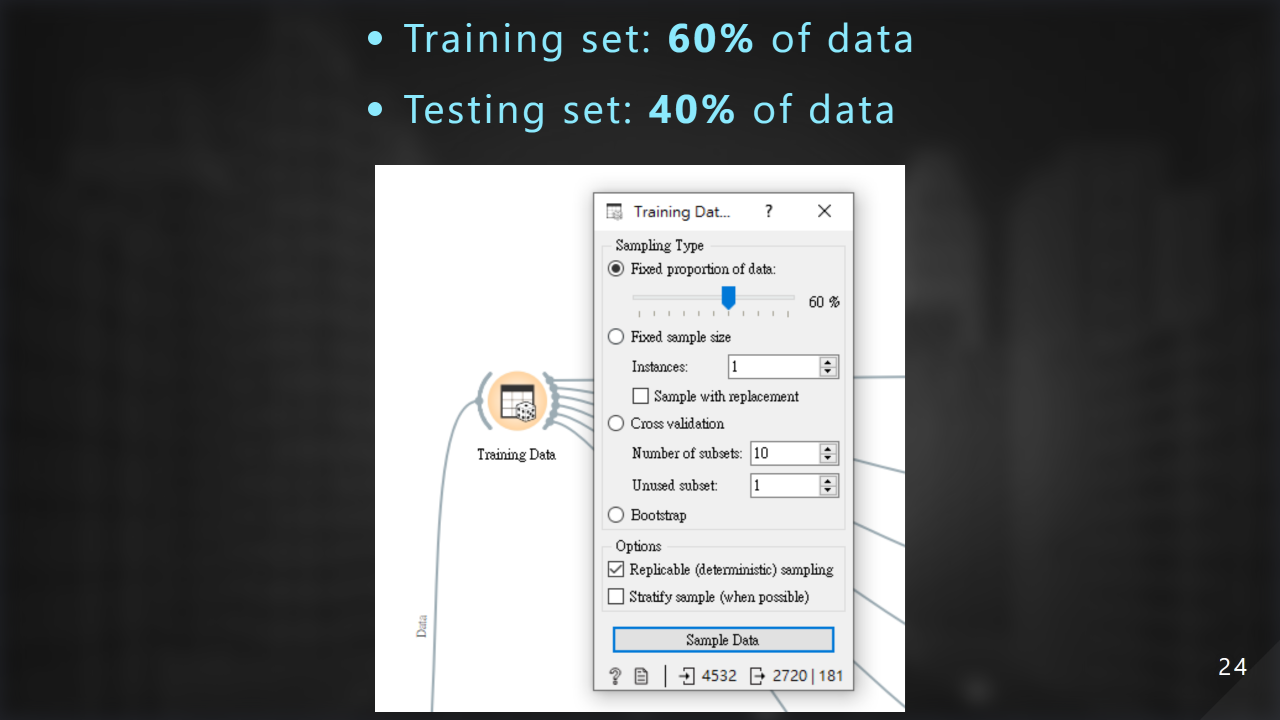
我們把 60% 的資料當作訓練集,40% 的資料當作測試集:
我們根據我們的資料型態選擇 4 種訓練學習模型,分別為 Naive Bayes、SVM、Logistic Regression 和 Neural Network 神經網路:

現在展⽰我們的實驗結果:

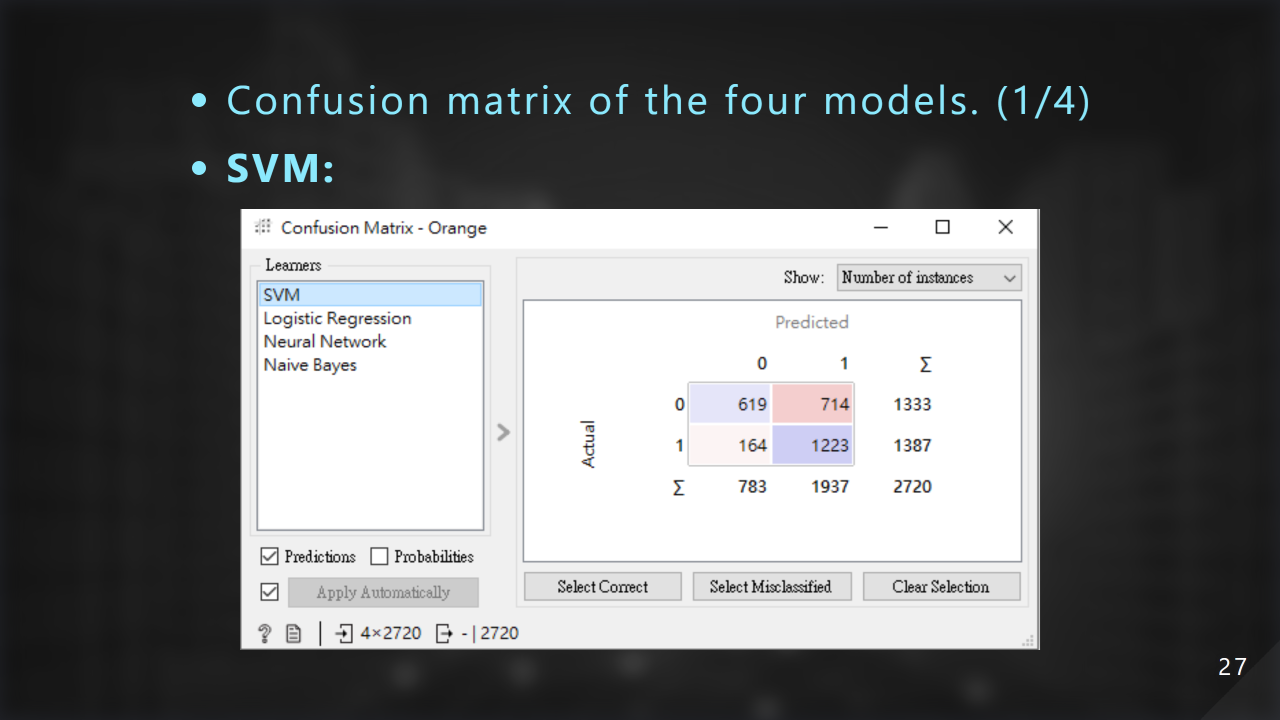
這是使⽤ SVM 的混淆矩陣:
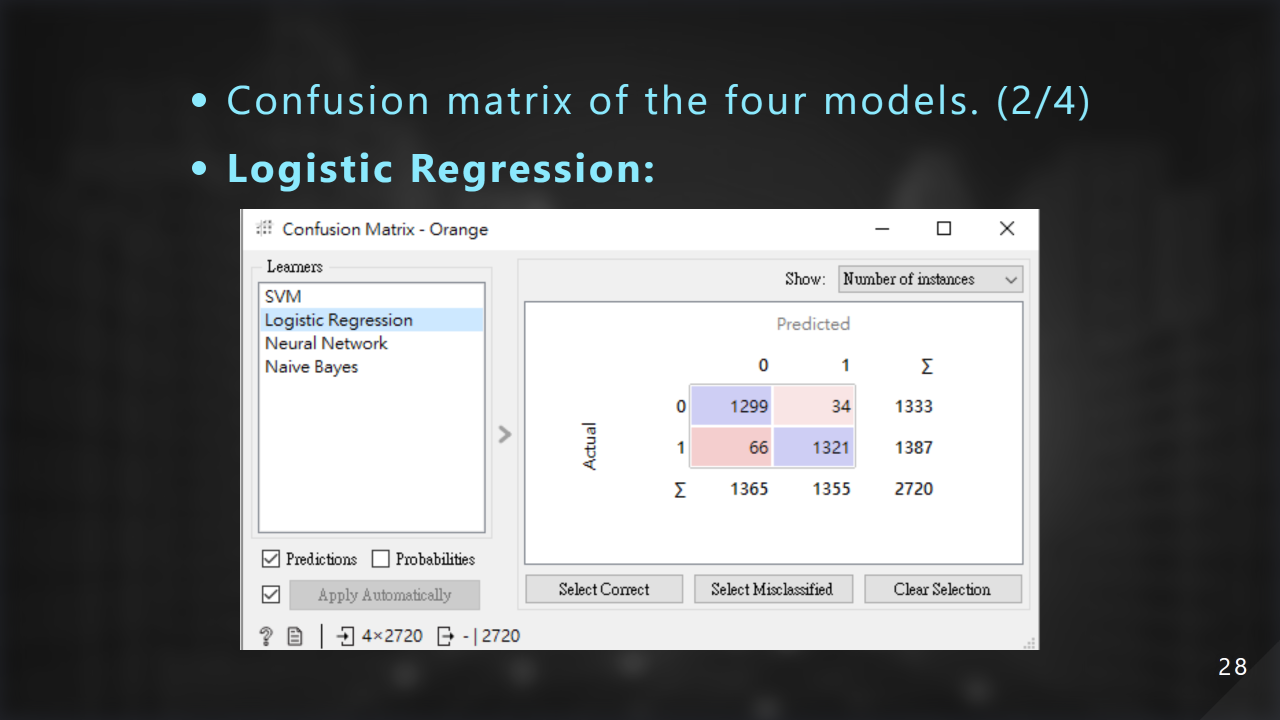
這是使⽤ Logistic Regression 的混淆矩陣:
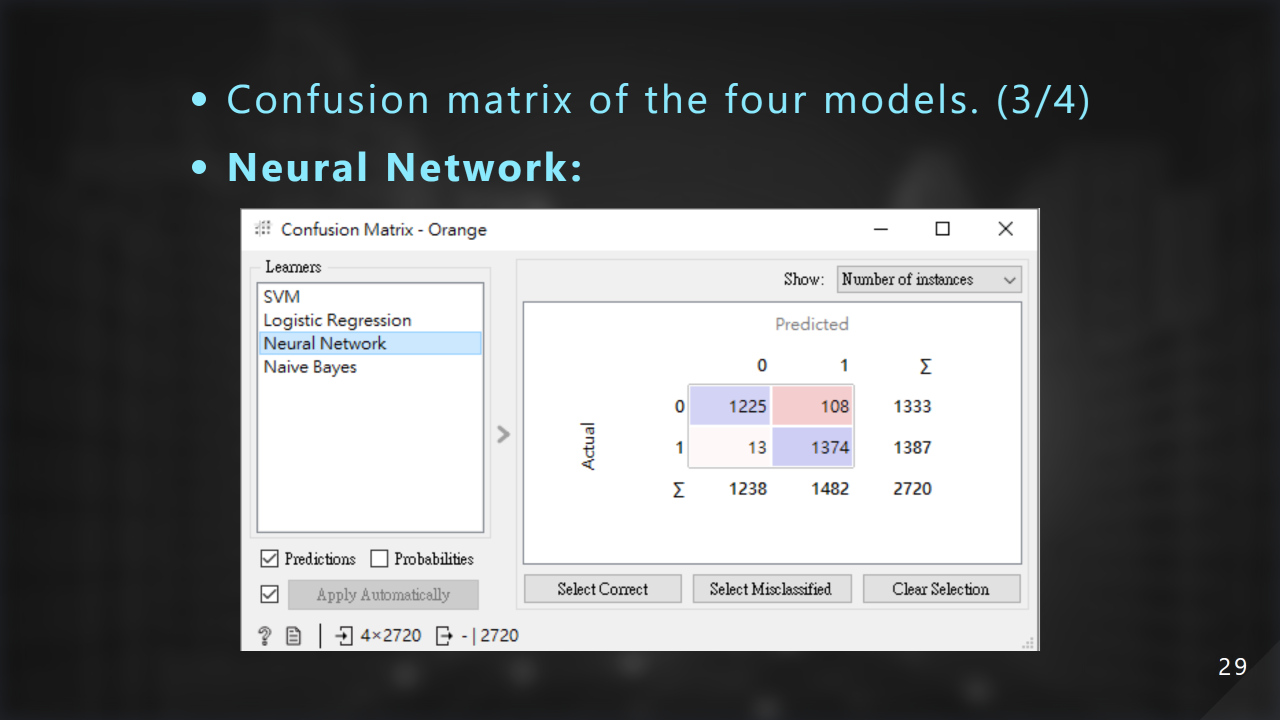
這是使⽤ Neural Network 神經網路 的混淆矩陣:
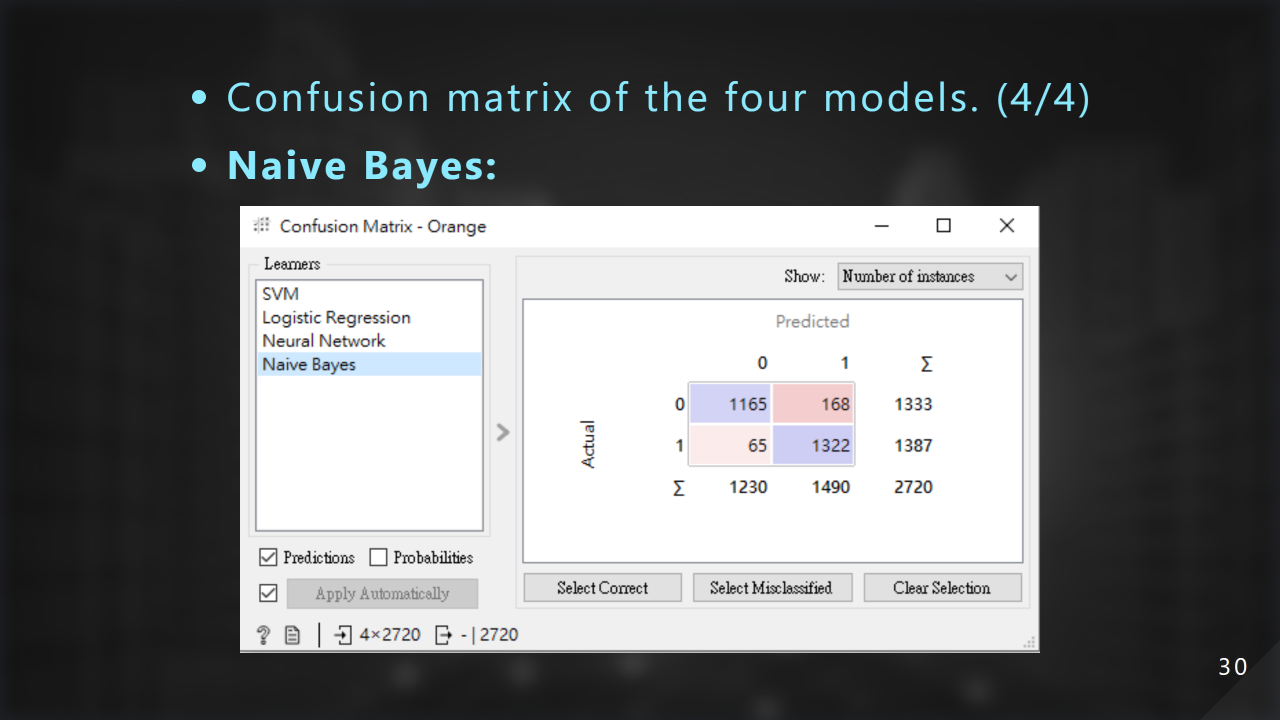
這是使⽤ Naive Bayes 的混淆矩陣:
這邊注意到我們真假新聞的比例為 1333 : 1387 接近 1 : 1。故我們使⽤準確率作為我們選⽤模型的依據:

Logistic Regression 和神經網路都有不錯的訓練結果,但是最終神經網路給我們帶來⽬前最好的結果,這邊是我們的訓練結果:

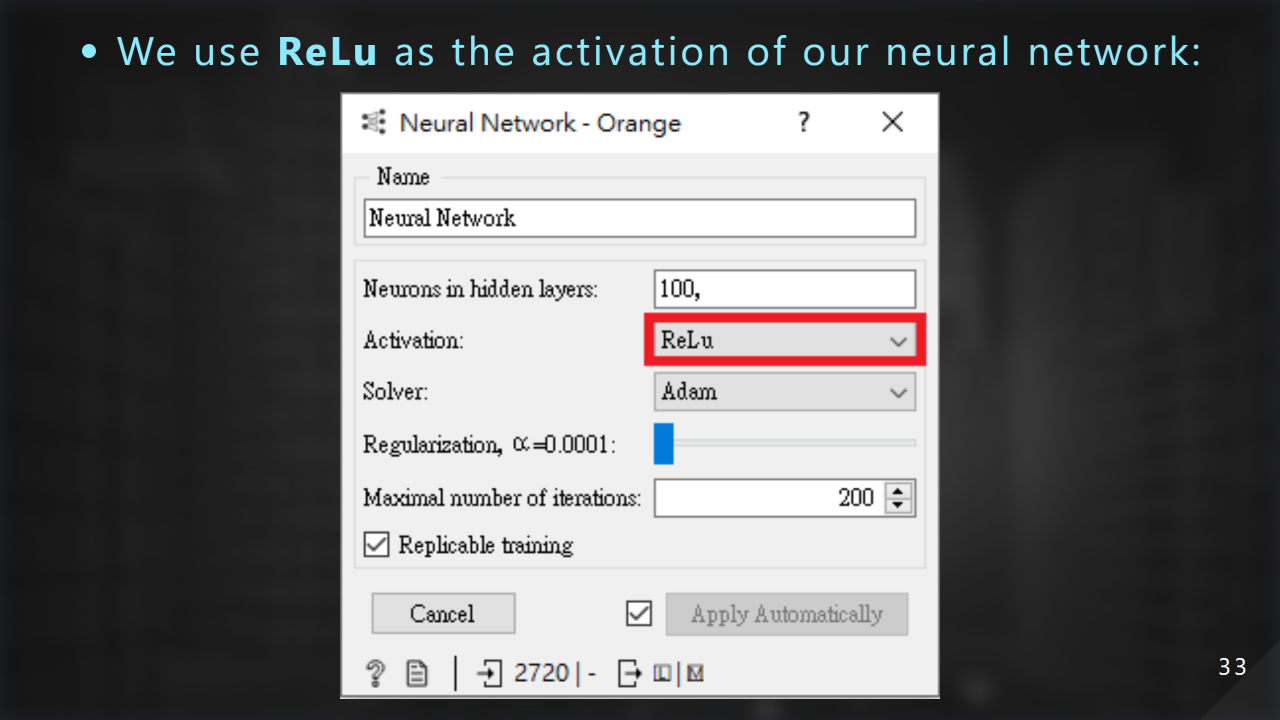
神經網路的 activate function 我們選用 ReLu:
這邊是我們的最終測試結果,準確率為 97.3%:
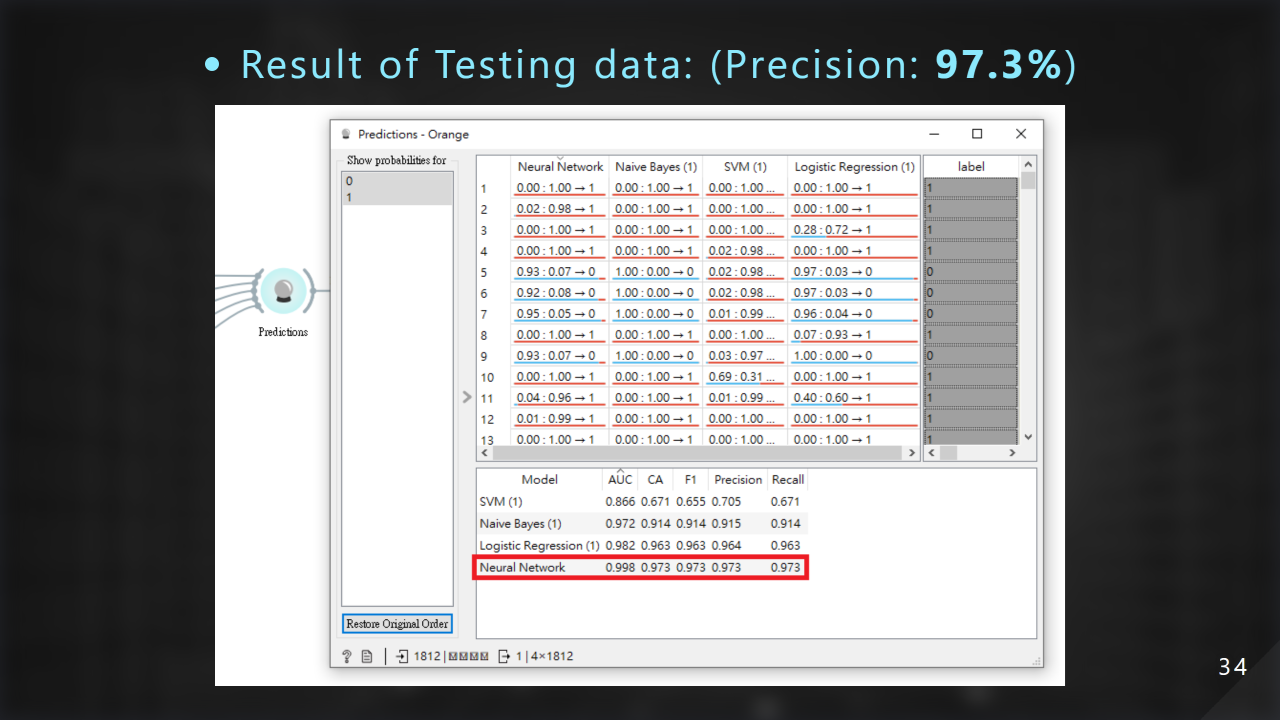
到這邊我們已經達到我們高準確率的目標了!

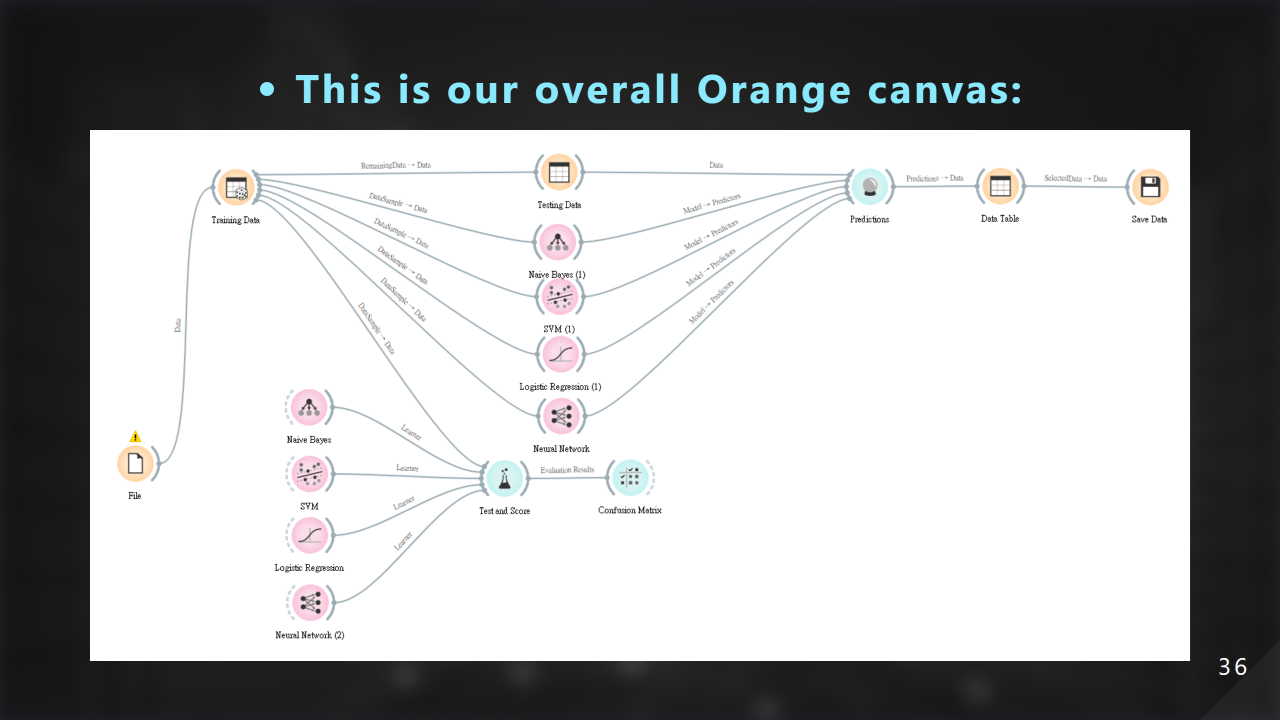
這邊是我們 orange 畫布的全部樣貌:
接下來總結一下我們所做的事情,大致分為前處理、訓練學習和實驗結果:

首先我們對文字進行了刪除 stop words 的動作,接下來利用 word2vec 以及 tfidf 方法把文章向量化以利我們進行學習:

接著我們使用神經網路加上 ReLu 的涵式進行訓練學習與測試:

最後我們得到 97.3% 的高準確率:
以下是我們其餘的簡報內容:




